数学和计算机科学板块_辛酸网
数据结构与算法9
BY TSherry
二叉树的遍历,就是一个一个访问其中的所有结点。要访问这些结点,就得按照一个合适的顺序。 二叉树也是树,树也是图,所以二叉树也是图,就遵循图所在遍历结点中的数学规律。和其它的图一样,二叉树的遍历可分为广度优先搜索和深度优先搜索两大类。 广度优先搜索在二叉树中也是层次遍历,顾名思义,就是一层一层遍历,不过是要从根开始的。 就比如下面的二叉树,按照层次遍历的顺序自根A始,就是按照字母的顺序ABCDEFGHJIKL。 而深度优先搜索在二叉树中通常有三大类型:先序遍历、中序遍历、后序遍历。
其中先序遍历的意思是:
首先访问根结点
然后先序遍历左子树
最后先序遍历右子树
而中序遍历的意思是:
首先中序遍历左子树
然后访问根结点
最后中序遍历右子树
至于后序遍历,则是:
首先后序遍历左子树
然后后序遍历右子树
最后访问根节点
不难看出这三种遍历都是递归式定义的。还以下图为例,从A开始如果要进行先序遍历,就先看其左子树, 左子树的根就是B,然后再看B的左子树D,而D的左子树就只有一个G。接下来开始回溯,访问D的右子树H……在B的这一部分访问完后,再对A的右子树也就是C这一部分开始深入。 把这些结点按照遍历的顺序一个一个写下来,就得到了遍历序列。现在我们看看怎么弄出这个遍历序列:一开始A下有BC,我们就可以写一个AB_C_,B下有DE,我们就将其补充为ABD_E_C_。 不过你可以看到E下面什么都没有,所以修正为ABD_EC_。D下的访问序列是GHJL,而C下是FIK,最后可得ABDGHJLECFIK。
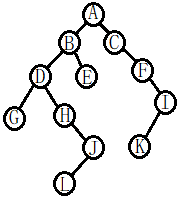
我们能看到在A的左子树中B为其根,所以A的左子树的这一段里,B是开头的。 反之在后序遍历中,A的左子树这一段B就是结尾的。如果我们把结点按照层次遍历的顺序,依照字母顺序命名,也就是说以ABCDEFGHJIKL这样的字母顺序,作为层次遍历的顺序, 那么我们可以根据先序和中序遍历序列还原出一整颗二叉树,或者按照后序和中序遍历序列还原出一整颗二叉树的样子。 就比如后序的DGLJHEBKIFCA,很明显A下有BC,我就知道DGKJHE一定是A的左子树的一部分,而KIF是A的右子树的一部分。 再结合中序的GDHLJBEACFKI,我就知道这其中E是B的右子结点,而DGKJH都在B的左边。C左子树空的,右子树下F在后序遍历序列的结尾,那么F就是C的右子结点……由此,这图中的二叉树就画出来了。
说实话我也不知道学这个有什么用,但考试就是要考。
先看一般树向二叉树的转换过程。在一般树中的子结点可以有多个,要变成二叉树就意味着其所有子结点都不超过两个。 这种转化非常简单,核心就两点:①兄弟结点中,兄作义父,弟作义子;②原子结点中,最大者为左,剩下的在右边。 在简体中文的互联网上曾经出现过一句非常难听的网络流行语“我好心拿你当兄弟,你却拿我当爸爸”,这是对第①条的通俗解释。 至于第②点,义子之义,在其归右。如下图中,CD为B之弟,化而为子,C作B右子结点;但C亦为D兄,故作D义父。 此处D是二叉树中C的唯一子结点,这里规定,如果子结点唯一则为左子结点。
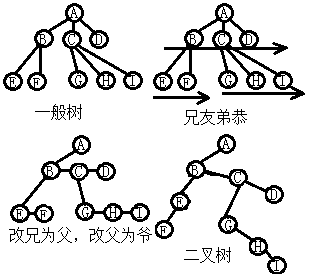
当然,对于一般树中不是大哥结点的子结点,原来的父结点自然就是爷爷结点。
二叉树变回一般树则恰好相反,前面说过,作义子者为右子结点,而义子之义子即为义孙(语出电视剧《朱元璋》),那么左子结点就是亲子,而义孙终归义孙。 所以转化过程是:二叉树中所有左子结点变为一般树中的大哥结点,右边的义子、义孙等归为小弟。
再看森林向二叉树的转化。
由上可见一般树变二叉树中除大哥结点外其它所有子结点都解除了与原父结点的父子关系,而二叉树中的右子结点就是原来的小弟结点。 所以你会发现在一般树中如果一个结点没有小弟结点,即为其父结点的唯一子结点,那么他就必然失去右子结点的来源,也就没有右子树。森林变成二叉树就是多棵树合并的过程。 因此其核心思想就是:找到右子树的空位,把其它的树放进去。但要把森林变成二叉树,就意味着把一棵树放入右子树的空位时,还能保证有新的空位供给下一棵树插入。
所以啥情况下保证一定有右子树的空位呢?我们知道在一般树中没有小弟结点的结点,变成二叉树后一定有右子树的空位。
而根结点是没有小弟结点的。所以,如果一颗一般树化为二叉树,你一定会在右上角发现一个可以插入二叉树的右子树空位。
因此,森林变成二叉树的方法就是:
哈夫曼树是树型数据结构实际应用中的最经典之作,它是一种信息压缩的手段。并且已经被发明者证明,这是信息在无损压缩下的数学极限。 信息的表示无非是用一种东西表示另一种东西,另外的东西表示其它的东西。一条消息或一份文件等,其中要表示的东西的种类数目总归是有限的。 我们对这些东西编码时当然要求每一种东西都有一个编码与之对应,但这并不意味着每一种东西出现的概率(或者说频率、次数等)是相等的。 出于简化考虑,不同的东西之间可以采用定长编码,但既然概率不同,那我们也完全可以使用变长的编码。
哈夫曼树的信息论核心就是:既然不同的东西出现概率不同,那就让出现多次的东西编码短,出现次数少的东西编码长。 罕见的东西用很长的编码专门表示以显重视不无道理,毕竟平时都会出现的东西都用长编码实在是浪费。那好,我们就统计这些东西各自出现的概率作为权重,权重越大,编码越短。 不过除了单独一个东西的权重外,东西的集合之权重也要考虑。
假设有这样一份特殊的文件,里面只有7个小写字母abcdefg,其出现频率如下:
| a | b | c | d | e | f | g |
| 0.08 | 0.25 | 0.34 | 0.1 | 0.07 | 0.1 | 0.06 |
既然eg出现概率最小,那么可以最为一个整体去研究,最后表示的时候如果前面的编码宣布了这个东西不是f就是g,那么我们就在后面再加一位0或1来区分e和g。 但是eg二者作为一个整体是不是还是概率最小呢?在别的例子里不一定,在这里则是:
| a | b | c | d | eg | f |
| 0.08 | 0.25 | 0.34 | 0.1 | 0.13 | 0.1 |
现在合起来最小的集合就是ad或是af也行。由此反复进行合并,直到变成一个东西就是这个文件的所有字母之集合:
| 轮次 | 此处加入的最小概率集合 | 编码状态 |
| 1 | eg | a0.08 b0.25 c0.34 d0.1 eg0.13 f0.1 |
| 2 | ad | ad0.18 b0.25 c0.34 eg0.13 f0.1 |
| 3 | efg | ad0.18 b0.25 c0.34 efg0.23 |
| 4 | adefg | adefg0.41 b0.25 c0.34 |
| 5 | bc | adefg0.41 bc0.59 |
| 6 | abcdefg | root1 |
种成一棵树,就是:
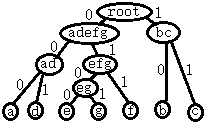
下一步,在所有的边上,左0右1写上去,或者反过来左1右0,从上往下读起来。如图,建立编码体系:
| a | b | c | d | e | f | g |
| 000 | 10 | 11 | 001 | 0100 | 011 | 0101 |
综上,哈夫曼树的构造过程是:
把所有的东西都摆出来,把权重最小的那两个合并为一个结点,其权重为两者之和,剩下的如法炮制,直到合出更结点。
这里的权重就是频率或概率、出现次数等。
哈夫曼树还解决的一个问题是如何构造前缀码——所谓前缀码就是说任意一个东西的编码不为另一个东西编码的前缀。
否则要是截取一个编码片段,你就不知道这是啥,如果例子中a用010表示,那么01010011110这个片段中你就不知道最前面是aa还是g,或者是ae?不知道。
哈夫曼编码是前缀码,没有这种会引起混淆的问题。
辛酸网 ©版权所有