数学和计算机科学板块_辛酸网
数据结构与算法8
BY TSherry
树,图论中的重要概念。树在文件系统、家谱绘制、基因谱系、数据压缩等应用广泛。 树是一种特殊的弱连通图,树中存在一个结点可以通向其它任意结点,叫做根。根不一定是唯一的,边也不一定是有向的。 如果根是唯一的,那就叫有根树,根不唯一的叫无根树;边有向的是有向树,反过来是无向树。 可见,“有根树”一词中“根”的含义不是说由此出发可走向任意结点,而是指唯一的根。当然,有向树一定是有根树。 另外要注意,树中没有回路,也就是说,从任意结点出发不管怎么走,只要不是完全不走就不可能回到起点。 一般而言,我们所讨论的树都是有向树,也就是说,存在一个唯一的根。
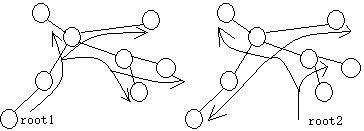
无根树的根不唯一,root1和root2都可以作为根
现在我们来看有向树。用一般图论观点看,结点所连的有向边,过来的边是入边,入边数目是入度;出去的边是出边,出边数目是出度。
树中结点有的只有入边,也就是说顺着边只能过来不能出去,出度为0,那叫叶子结点;有的有入边也有出边,顺着边可以过来也可以出去,那是内部结点也是分支结点;而根则是没有入边只有出边,顺着边只能出去不能过来。树中所有结点,除了根结点入度为0,其余入度皆为1。树整体的度是广度,即所有结点的出度中最大的那个数。
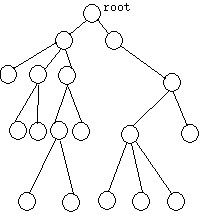
此外我们看树的样子,作为数据结构而存在的树,和作为植物而存在的树是两个不同的东西,前者的根往往是在上面,而后者的根却是在下面。至于为什么这样画,我也不知道。反正我们看这树的样子,一看就是一层一层的。最上面那层就一个结点,根;最下面那层一定是叶子。但是叶子不一定在最下面的那层。至于一个结点到底在第几层,不同的人采用的标准不同。有的人称根所在的那一层为第0层,而有些人却称之为第1层。树的深度就是最大层数。
二叉树的度为2,每个结点最多两个子结点,一个叫做子结点,一个是右子结点。因为子结点也可以单独构成一棵树,故这两个又是左子树和右子树。
至于为何二叉树不是度为2的一般树,在于子结点的顺序问题。对于无序树,如果一个结点有多个子结点,则这两个子结点一定是在概念上不能相互区分的,也就不能做出相应的排序。而有序树中如果一个结点有多个子结点,那么这些互为兄弟的子结点在概念上相互之间是不一样的,是可以并已经排序了的。有序树中的多个子结点会有老大,老二等,但是如果只有一个子结点,那么这个子结点就一定是老大结点。这样一来,度为2的一般有序树,如果一个结点有两个子结点,那么这两个子结点一定会有一个是老大而另一个是老二,如果只有一个子结点,则这个子结点就是老大。然而二叉树的情况不一样,二叉树的结点如果有两个子结点,那么这两个子结点一个是左子结点一个是右子结点,如果只有一个子结点,那这个子结点可能是左子结点也可能是右子结点。
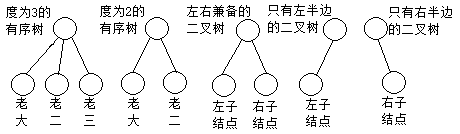
如上图,二叉树中左子树可以脱离于右子树而单独存在,右子树可以脱离于左子树而单独存在。但是度为2的一般有序树中,老大可以脱离于老二而单独存在,老二不能脱离于老大而单独存在。所以二叉树是特殊的树。
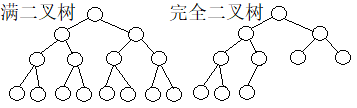
二叉树有的完整有的不完整。完整的二叉树,所有叶子都在同一层,并且这一层的叶子足够多,多到不能再多了,直观地说就是满了。如果一棵二叉树不增加深度就不能再增加结点,因为结点多到不能再多了,那就是满的,叫满二叉树。如果二叉树里除了最底层外,上面的是满二叉树,而下面最底层的都聚集在最左边,则这棵二叉树叫完全二叉树。
由于树中的结点有各种各样的关系,所以你不仅需要存储各个结点内部的信息,这些结点相互之间的关系的信息你也需要存储。你可以将这些关系的信息存储在结点内部,也可以制定一套访问规则来存储这些关系的信息。而具体要放或者说直接关注哪些关系的信息,有三种大体的情况:父结点表示法、孩子结点表示法、孩子兄弟表示法。
其中,父结点表示法是指:对于每一个结点,你不光要记下这个结点是什么样子的,还要记下其父结点是哪一个结点。
孩子结点表示法是指:对于每一个结点,你不光要记下这个结点是什么样子的,还要记下其子结点是哪几个结点。
孩子兄弟表示法是指:对于每一个结点,你不光要记下这个结点是什么样子的,还要另外记下其子结点和兄弟结点是哪几个结点。
例如,你可以用一个数组去存储其中的结点,每一个结点内都写着自身的值和父结点的下标。这样当你访问其中一个结点时就可以找到其父结点。这就是父结点表示法。
| 序号 | 值 | 父结点下标 |
| 0 | a | 此为根 |
| 1 | b | 3 |
| 2 | c | 3 |
| 3 | d | 0 |
| 4 | e | 3 |
| 5 | f | 2 |
| 6 | g | 1 |
| 7 | h | 2 |
这是一棵三叉树,a为根。这种在每一元素里有附加项记录下邻接结点是哪个的数组,叫邻接表。
如果要问e的父结点是哪个,你可以立刻回答说d。但是问你d的子结点有哪些,问你e的兄弟有哪些,你就得遍历这个数组去寻找了。另外两种表示法也是一样的道理,单向寻找最为合适。当然你也可以把父结点和子结点、兄弟结点的位置都记下来,只是有点费空间。除了邻接表,你还能用指针来做。对于二叉树的孩子结点表示法,有leftchild和rightchild两个指针:
typedef struct node{
DataType value;
node* leftchild,rightchild;
}; 这种方式也叫二叉树的二叉链表存储。除此之外,二叉树还可以顺序存储。
我们前面说过,如果这些结点间的关系的信息不在结点内部存储,我们就可以通过特定的访问规则来实现关系的存储。
一棵具有n层的二叉树,最多(2n-1)个结点,放到一个数组里,最大也是2n-1的大小。
当我们把一棵满数的结点,从根的那一层开始,一层一层,从左向右一个一个数,还从1还是编号的话,我们会发现一个很有意思的现象:第i号结点的左子结点编号2i,右子结点编号2i+1。
那对于一棵满数我们就能开个大小为2n的数组,对应编号存储。
现在,寻子结点只需编号乘以2,大于2n者为叶子,否则按编号直接访问即可;寻父结点,只要不是根,编号除以2向下取整就行。
这便是二叉树的顺序存储。
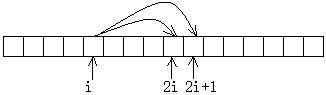
这种存储的缺点是:只有满二叉树下数组是满的(除了0号,不过你倒是能往前推一下,又节省一个元素的空间),其余情况下都有空余的空间,还一般来说不能用。 每个数组元素内都有打标记表示这里有没有结点。故二叉树的顺序存储,非常浪费空间。一般树的顺序存储与之类似,所以链式存储更为常用。
辛酸网 ©版权所有