数学和计算机科学板块_辛酸网
数据结构与算法7
BY TSherry
高数数组,其实就是数组的数组。二位的那叫矩阵,也是最常见的高维数组了。因为更高维的太复杂,不好用。二维的数组有时人们管这叫矩阵,有时叫表,有时甚至是叫关系。不过在数据结构的话题下,人们还是更习惯叫它矩阵,一般来说最简单的都是顺序存储的。这就带来了一个问题。矩阵有行有列,既然是顺序存储,就得知道在物理结构上,是什么东西和什么东西会挨在一起。如果是同一行的内容放在一起,不同的行再相互挨着,不同的的列再相互交叉地放着,那就是按行存储;如果是同一列的内容放在一起,不同的列再相互挨着,不同的的行再相互交叉地放着,那就是按列存储。建立一个二维数组在内存中,到底是按行还是按列存储,这要看编程语言了。一般来说,C语言中的二维数组是按行的。但是在一种上古传奇文字Fortran中却恰好相反是按列存储的。
如果你不搞数据库和操作系统的研究,那这两种存储方式对你而言最大的区别就是,写代码时下标的顺序不一样。用C语言写代码时你会发现申请一个数组,里面的那个维度的中括号是写在右边的,而外面的那个维度,也就是作为一个数组而包含了更小的数组的数组的那个维度,中括号是写在左边的。例如,我说有char a[m][n]; 这样的代码就是有一种char数组,其内包含了n个char字符,而另外还有一种数组,其内包含了m个这样的char数组。长度为n的char数组,实际上是另外一种长度为m的数组之元素罢了。但是Fortran不一样,是恰好相反的。
我们知道内存可以被看做一个巨大的字节数组,其它的很多存储器其实也这样。物理上按行存储,在数据库中就是一个元组一个元组地放。而按列存储则是一个属性一个属性地放。如果我就是单纯地做选择运算我就可以遍历元组构成的数组,一个一个看,把符合条件的都拿出来。但如果是单纯地投影运算,我就把整张表读一遍了。而按列存储恰好相反,如果我是单纯地做选择运算,我就得读遍整张表把对应的元组凑出来,而在投影运算中不然,直接把需要的列摆出来即可。针对公司里这样的一个表格:
| 张三 | 普通职工 | 3000 |
| 李四 | 普通职工 | 3500 |
| 王五 | 高级工程师 | 8000 |
| 孙六 | 销售 | 5000 |
在内存里如果是按行存储是这样的:
| 张三 | 普通职工 | 3000 | 李四 | 普通职工 | 3500 | 王五 | 高级工程师 | 8000 | 孙六 | 销售 | 5000 |
按列存储的画风是这样的:
| 张三 | 李四 | 王五 | 孙六 | 普通职工 | 普通职工 | 高级工程师 | 销售 | 3000 | 3500 | 8000 | 5000 |
显然,一问张三情况如何,按行存储的读起来快。一问所有普通职工的工资,按列存储的读起来快。只是这公司只有4个就有点离谱,所以第二个的每一列之间还要空开点。顺便一提,因为按行存储涉及结构体或者类和对象,所以更容易有冗余信息,空间利用率往往比较低。但按列存储的话,你写了一列又一列,你能保证每一列都一样长吗?恐怕不一定,写到后面说不定有的元组的某些信息你就忘了写了。可没有数据的地方,哪怕是空的NULL也得给我写上!要不然的话有的元组里面,有的属性存在了,有的属性就没了,那就悲催了。而按行存储时你要对每一个元组一个一个看,遍历其中的属性,就不容易忘了写。所以数据完整性上按行存储优于按列存储。
对称矩阵,上三角矩阵,下三角矩阵的压缩存储本质上一个道理。因为这三种矩阵都是只考虑对角线及其一边的内容,剩下的都知道了也就不用再占用空间了。当然,如果情况再夸张点,是对角矩阵的话那就干脆当成一个向量来个一维数组去存储得了。现在我们看矩阵 如果它是一个对称矩阵或者下三角矩阵,那就存储左下部分即可,此时我们需要关注的矩阵内容是 当然啦,这样的矩阵都是方阵,m=n的。自首行始,第1行有1个,第2行有2个,第i行有i个,最后是n个。所以一共需要存储个元素。将其放在一维数组A中,a11=A[0],a21=A[1],对于一般的元素aij,我们知道其上有(i-1)行,有个,而同一行的前面有(j-1)个。所以在A中元素aij前有个元素,于是这就是其下标。
但右上角部分呢?如果是对称矩阵,那就和对应的左下部分一模一样,如果是下三角矩阵,那就是0,也就懒得去想什么。总之,对于对称矩阵而言,
其元素的值 而下三角矩阵就是在这个表达式的下面那部分为0便是。上三角矩阵的存储同理。
稀疏,稀者,少也,疏者,远也。稀疏,就是值不是0的东西又少又远。稀疏的东西若直接存储下来就会有大量的0占据大量空间。但到底多稀多疏算是稀疏?有兴趣找虐的点击知乎上的这篇文章如何度量数据的稀疏程度?稀疏的可以是矩阵,特殊点,也可以是高位向量,对于这个有兴趣找虐的麻烦去看CCFCSP2020年6月第2题讲解
一个不为0的元素,我们要记录下什么呢?最核心的无非有三:在第几行,在第几列,等于几。也就是知道这是个啥以及这玩意在哪。但是矩阵是有大小的,我们不能保证最后一行和最后一列上一定不空,所以我们需要另外记下这个矩阵的大小。见下:
#include<vector>
typedef struct MATelement{
int row,column;
float value;
};
typedef struct sMAT{
int rownum,columnnum;
vector<MATelement> *pEs;//pEs指向Es
};一般来说为了方便做一下复杂的处理,我们要确保那个数组Es中的内容,以矩阵中实际位置为依据,是有序的。此时你应该选择按行存储或按列存储。现实中要求会再变态点:倘若整体按行存储,同一行内元素按列号从小到大放。
单纯地说矩阵的转置,就是翻一下,无非每一个元素的两个下标互换。但是稀疏矩阵中我们往往要面临这样的要求——内部元素的地址必须是按照实际位置而排列的,如果转置前是按行存储,那么转置后也是按行存储;转置前是按列存储,那么转置后也是按列存储。别想着row和column互换一下而已的这种复杂度为n的美逝。那最无聊的行为就是先把这件美逝干了,row和column互换,以按行存储为例,这时数组中的row应该会从有序变为了无序。那既然row是无序的,那就再排序一下变得有序。但是排序嘛,不管你怎么排序,学术界已经定下来了,起码也得是个nlogn的时间复杂度,取最大数量级你也得nlogn哈。
我们知道转置前的行是转置后的列,转置后的列是转置后的行。转置前同一列的就应该是转置后同一行的。在总行数和总列数是已知的,现在设立一个vector指针pES2指向Es2。接下来,请设立循环变量i从1到columnnum。当i==1时我们遍历Es,将其中的第一列元素复制到Es2,这就相当于遍历了原矩阵的第一列。之后i反复增加,每次都要遍历Es中剩下的部分,将那些位于第i列的元素一个一个添加到Es2里,顺便坐标换换。就这样,我们先后将Es中每一列的元素一个个按行数顺序放在Es2内,使得Es2成为了最终转置后的结果。当然,Es2也是稀疏的。最后我们用指针pEs=pEs2一步到位就算法结束了。(等等,别忘了rownum和columnnum换下!)
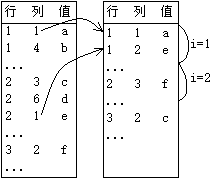
由于参与复制或转移的元素就是那些不为0的东西,所以时间复杂度就是n。
辛酸网 ©版权所有