数学和计算机科学板块_辛酸网
数据结构与算法10
BY TSherry
我们知道二叉树在遍历中结点是有顺序的。 线索二叉树是指,在结点上增设两个属性用于记载在遍历中前一个和后一个结点是哪个的二叉树。 每一个结点上都有pre和next两个成员告诉我们在二叉树的遍历中,要遍历当前结点的话,要遍历的前一个和后一个结点是什么。 将一般的二叉树变成线索二叉树,这种行为叫做线索化。最基本的线索二叉树结点格式当然是:
| pre | leftchild | self.data | rightchild | next |
但我们知道整个遍历顺序中肯定有一个最前面的没有遍历过程中的前驱,肯定有最后一个结点没有在遍历工程中的后继, 有的结点无左子结点,有的没有右子结点。所以这五大项内除了data是必然存在的以外,其余的都可能不存在。一旦这四个里有一个为NULL那就和不需要存储没啥区别。 那不就浪费空间了么?先序遍历中根是先进行的——只要左子结点存在,那一个结点的遍历过程之后继必然为其左子结点;左子结点不存在,那下一个就是右子结点; 右子结点也不存在,它是叶子,那下一个就是要往上回溯。类似的后序遍历中情况也是复杂的。但转念一想,我们又不是只有先序和后序遍历, 还有中序遍历呢。中序遍历的情况较特别。
中序遍历是“左根右”的逻辑,也就是说只要有左右结点,编历时,前一个就是左子结点,下一个就是右子结点! 如果左右结点不存在,那就另当别论了,但只要有,那左子结点和前驱结点就是同一个,右子结点和后继就是同一个。这种必然性的规律使得二者存储空间可以合并。 但你怎么知道有没有左右子结点呢?那就再设两比特内容分别表示有无左右结点。这样一来,线索二叉树的结点就长这样:
pre_or_leftchild | lefttag | self.data | righttag | next_or_rightchild |
pre_or_leftchild代表左子结点 在lefttag=1时 否则,仅代表前驱
next_or_righttchild代表右子结点 在righttag=1时 否则,仅代表后继
对应的线索化方法是:
改leftchild和rightchild为pre_or_leftchild和next_or_rightchild。
如果发现该结点有左子结点
设自身lefttag为1,设pre_or_leftchild为左子结点;
如果左子结点无自身的右子结点,即其righttag为0
则其next_or_rightchild指向当前结点
如果发现该结点有右子结点
设其righttag为1,设next_or_rightchild为右子结点。
如果右子结点无自身的左子结点,即其lefttag为0
则其pre_or_leftchild指向当前结点
顾名思义,二叉排序树是拿来排序的二叉排序树。这种树的核心特点是:
每一个结点上有一个数,凡是左子树里的结点,数都比它小,凡是右子树里的结点,数都比它大。(左右反过来也行)
用二叉树排序的方法非常简单:先拿一个数过来作为根节点,然后从原来乱序的数每次遍历出一个数时,就从根结点开始一个一个比较。
凡是比当前结点小的数,就放在左边,和左子树的根比较,接下来如法炮制;
凡是比当前结点大的数,就放在右边,和右子树的根比较,接下来如法炮制。
话不多说,上例子:
61 67 11 98 88 40 52 58 16 80 42 25
①61作根,67>61,为右子结点;11<61,为作子结点
②98最大,放右下角67之右;
88>61,归右,88>67,归右,88>98,98左子结点
③40<61,归左,40>11,11右子结点
④52<61,归左,52>11,归右,52>40,40右子结点,同理,58为52右子结点
⑤16<61,归左,16>11,归右,16<40,40左子结点
⑥80>61,归右,80>67,归右,80<98,归左,80<88,88左子结点
⑦42<61,归左,42>11,归右,42>40,归右,42<52,52左子结点
⑧25<61,归左,25>11,归右,25<40,归左,25>16,16右子结点
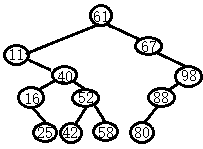
此树之子结点,凡左者小,而右者大,故自小而大,当左根右之序。对其中序遍历,当有:
11,16,25,40,42,52,58,61,67,80,88,98
排序完毕。
辛酸网 ©版权所有