数学和计算机科学板块_辛酸网
数据结构与算法17
BY TSherry
首先我们得明确,所谓时间复杂度的概念严格地说指的是渐进时间复杂度,也就是说不同算法间时间复杂度的比较不完全是消耗时间的比较, 而是数量级的比较。如果说随着问题规模n的不断扩大,算法消耗时间f(n)和另一个关于n的函数g(n)成了同阶的无穷大,那么这种情况就叫做f(n)=θ(g(n)); 如果g(n)是f(n)更高阶的无穷大,则g(n)就是时间复杂度的渐进上界,这种情况叫做f(n)=O(g(n));反之,f(n)是g(n)高阶无穷大的话,则记作f(n)=o(g(n))。 即使是同一个问题的同一个算法,在问题的不同输入下也程序可能有不同的表现,概括地讲就是最好、最坏、平均三种时间复杂度取值。不过,我们一般说的是平均。 甚至很多时候O和θ是混淆的。
因为时间复杂度比较的是数量级,所以很多时候表达式中具体的系数和常数会被无视,经常是直接写作1。 不同的数量级大小关系,从小到大大体是:
| 1 | logn | n | n2 | n3 | ... | 2n | ... | n! |
| 常数级 | 对数级 | 多项式 | 指数级 | 阶乘 | ||||
对数级的复杂度,通常以2为底。需要注意的是,上面多项式和指数级的时间概念是狭义的。 广义上说,从常数级到n的若干次方都是多项式时间,比这个更大的都叫做指数时间。当问题规模足够大,多项式时间的算法会被认为是在数学上可接受, 但指数时间的成本太大,往往被认为是不可接受的。
输入低的时间复杂度意味着程序运行有节省时间的能力,但在实际编程中,我们还需要警惕时间复杂度。 低的时间复杂度真的一定能带来更高的效率吗?其实也不一定。有两种情况会使得结果完全相反:
①问题规模不大,使得时间复杂度的低数量级优势无法体现出来, 例如,O(n)<O(1.3n),但在n<7.857时n>1.3n,使得一个复杂算法在小问题中反而优于简单算法。 其实TCP的慢开始与拥塞避免策略中就是这样应用的。
②编程语言不同,同样的算法用C和Python写速度差异是极大的。编译型语言快于解释型语言,高概率的缓存命中优于低概率的, 这种差异有时甚至能盖过时间复杂度的数量级差异。
递归树是一种用于求递归方程的数学工具。能用递归树计算的时间复杂度往往是f(n)=af(g(n))+h(n)之形式。 在具有这种时间复杂度的这种算法里,一个规模为n的问题被化解为a个规模为g(n)的子问题,是为分治。 其中a通常为正整数,f(g(n))是小于f(n)的子问题规模,h(n)表示将子问题的解合并成为整体问题的解,所需要的代价。
现在对此画递归树:递归树中的每一个结点表示一个子问题,结点中有两个参数,一个是这个子问题的子问题的总规模, 另一个是吧更小的一级子问题的解合并,形成当前这个子问题的解所额外需要的代价。例如递归式 , 每个子问题都被分为两个更小的子问题,解的合并代价等于当前子问题规模。就比如,现在画递归树如下:
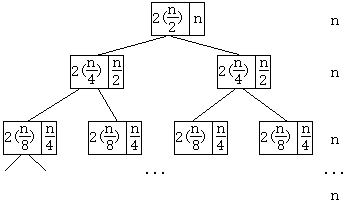
在根节点处,整个大问题的时间复杂度是f(n),分为两个子问题,
将两个子问题的解合并为整体解额外要花n的代价。而那两个子问题的代价都是
,
这两个子问题的又分别由更小的子问题的代价构成。
在第二层,每个规模为的子问题又是由两个规模为
的子问题构成,
相应地,在第二层的每个子问题中,解的合并代价为,
因为第二层有两个子问题,所以这一层的解的合并代价就是。
以此类推,第三层有4个规模为的子问题,
每个子问题内部的解合并代价也是,
这一层的解合并代价就是。
以此类推,在递归树中每一层的结点都有在这一层的解合并代价,把它们加起来就能成一个数列,接着数列求和就是整个问题的总代价。 也许有人要问,一个子问题内部除了它所在结点的合并代价以外,不是还要更小一级的子问题的代价么?是这样的没错,但是,更小子问题的代价是怎么算的呢?依旧是递归的过程。 所以,上一层的内部子问题代价就被摊到下一层了,更小一级的子问题代价又继续向下摊分,直到叶子结点,也就对应于不能再继续分割的最小子问题。
在上面的例子中,每一层结点的合并代价都是n,因为长得像满二叉树所以我们不难看出一共log2n层。 所以我们说这个算法的时间复杂度为
接下来请动用概率论和统计学的知识想一想,如果每次子问题分解成的子子问题数目不固定会怎样?如果子问题数量不是正整数会怎样? 此时a也不一定是正整数了,我们只能说需要一个一般化的数列求和。不过对于某些问题,还可能有主方法来解决。
主定理的内容是这样的:如果一个递归方程满足,则f(n)满足:
①当d<logba时,f(n)=O(nlogba)
②当d=logba时,f(n)=O(ndlogn)
③当d>logba时,f(n)=O(nd)
辛酸网 ©版权所有