数学和计算机科学板块_辛酸网
数据结构与算法16
BY TSherry
“查找表”是一个多义词,有硬件和软件的两层含义。在硬件层面上,查找表是指FPGA芯片中真值表的基本单元。 在软件层面,查找表是一类线性表,着重于查找的工作。查找表中的元素往往是一个结构体或者对象,其成员变量叫做元素的关键字。 程序员可以以关键字为指标在查找表中选择,找出需要查找的元素。但是不同元素的同一成员变量取值也可能相同,这样当我们要唯一确定一个元素时, 需要指定一个不可能在不同元素间重复取值的成员变量,这就是特征关键字。在数据结构的资料里,“关键字”一词通常指特征关键字。
在查找表中寻找一个元素,最简单的方式就是顺序查找,从头到尾逐个匹配关键字,相同的话就表明找到了。 这时,查找表的末尾就要另外设立一个存储空间,打上特殊的标记,称为岗哨位。岗哨位的存在宣告了查找表的边缘, 一旦查找工作中搜到了岗哨位,就说明整个查找表已经遍历完了,这时还没找着只能说明要找的元素中整个查找表中不存在,所有的都不匹配。 当然,如果你不是从头到尾查找而是反过来从尾到头查找,那岗哨位就应该放在开头而非末尾。显然,这种最简单的顺序查找要O(n)的时间复杂度。
所以有没有一种更快的查找方法呢?如果关键字的值可以排序,有了大小之分, 那么在把元素存储在查找表内部时,我们就能设法确保这些元素是有序的。按照关键字的值,在存储时提前排好序后,翻一翻高中的数学课本就不难想到使用二分法。 二分查找又叫折半查找,其工作内容如下:将搜索范围分为高低两部分,直接取最中间的元素的关键字和待查关键字进行比较, 最中间元素的关键字高了就看高部分,设为新的下一轮搜索范围;低了就看低部分作为下一个搜索范围。如果搜索范围的元素个数是偶数怎么办?向上向下取整。见例:
| 2 | 8 | 26 | 42 | 71 | 77 | 82 | 84 | 86 | 96 |
寻找元素82
取最中间元素71,小了,选右边77-96
取最中间元素84,大了,选左边77-82
取最中间元素77,大了,选右边的82,命中
据说中国央视以前有一档节目叫《购物街》,里面就有猜价格的环节,这就是二分法的典型示例。
尽管确保元素有序的前提下二分查找时间复杂度是对数级的,倘若元素总量足够多,就比如说是一亿个,还是要消耗不少时间的。
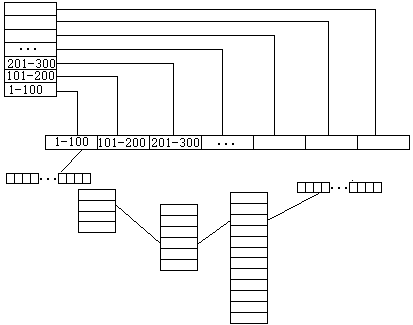
一级和多级索引
但如果我们将这些元素分类,每一类单独建立一个格子,称为索引项,每一个索引项下设一个表格,将这一类的具体元素存放其中, 那么,每次查找元素时只需要根据关键字的值判定这个元素属于哪一类,就知道对应着哪个索引项,再找对对应的表格,这样一来每次查找就只需要在这个局部而非整体的表格中找, 于是查找需要的时间就大为节省。例如上图中关键字为226的元素,因为201<226<300,所以我们锁定“201-300”这个索引项,只在那最多100个元素的表格中寻找。
当然,就像现代操作系统的内存分页机制可以是多级页表一样,索引存储中,如果把索引项也看做一个元素,一个东西, 那么对索引项进行分类还能得到索引项之索引项,那么对具体元素的查找就成了先判断大类后判断小类,最后进行具体搜索的过程。此之谓多级索引。 另外,要是某一级或多级是有序的话,在有序的地方进行二分查找也不是不行。在元素数量极大的情况下,索引存储无疑提高了效率,却也不可避免地浪费了大量空间。
在多级索引存储下,高级索引的一个索引项对应着低级索引的一个索引项之表格。然而在确保索引项和被存储元素有序之前提下, 若是,与,低级索引项乃至具体元素的表格,相对应的,并不是一个高级的索引项,而是高级索引项之间的间隙呢?这样一来种出来的树就叫B树。 例如,一个高级索引项的表格有三个关键字的值:100,200,300,而在这高级索引项表格之下还有一个低级索引项的表格,其内有索引值230和260。 此时,这个高级表格有4个间隙——比100小的,100到200之间的,200到300之间的,大于300的。那个低级表格也有3个间隙:小于230的,230到260的,比260大的。 因为这个低级表格及其下设的元素,关键字的值都在200到300之间,所以,我们就把这个低级表格划归到那个高级表格之下,且对应于200到300的这个间隙。
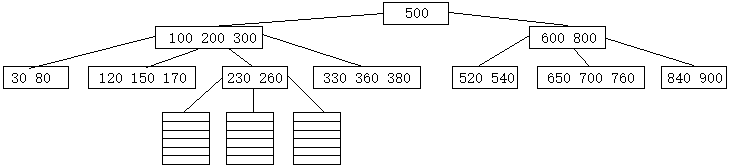
对此,仿照二叉排序树的概念,我们规定下面的那个低级表格,关键字最大最小也不能不超过上方间隙的范围。
例如,见上图,搜索关键字为273的元素,步骤如下:
小于500,往左
在200到300之间,寻该结点下设的第3个表格
大于260,寻该结点下设的第3个表格进行具体查找
和一般树有度的概念一样,B树也是树。B树中一个结点即为一个表格,其最大的间隙数量叫做B树的阶。 但B树中使用者真正要寻找的那个目的,一定在最低级的表格是,只要要查的元素存在,那就是叶子结点,而二叉排序树中要找到那个元素却不一定是叶子。 故二叉排序树不是阶为2的B树。
B树有变体B-和B+树,是索引存储的高效利用,能在上千甚至上亿个元素中仅靠数次即完成查找。
我记得B+和B-树考研不考,就鸽了吧。
哈希,什么是哈希?哈希有单向性,有一定但不彻底的抗碰撞性,有哈希存储和消息摘要的应用。无论是什么样子的哈希, 我们都可以根据其本质特质找出其该有的定义:从无限或近于无效的内容到有限空间的对应映射。 哈希存储往往被用在极大量的信息的存储中。同样地,对于被存储元素我们还要使用特征关键字的概念。 现在有这样一个很大的空间,空间里有一个个格子,每个格子仅可放一个元素。对于一个关键字为x的元素,我们该把它放在哪里呢?现在定义一个函数f(x), 使得根据关键字x的值,函数值h=f(x)即为该元素应该存放的格子的编号,也就是地址。
但万一有两个关键字x1,x2造成f(x1)=f(x2)怎么办? 像这样不同输入碰巧带来同样哈希输出的情况就是哈希的碰撞。这时不妨设关键字x1的那个元素是先放在哈希表中的元素。 首先,把关键字x1的这个元素放在h1=f(x1)处,接着,在编号为h1的格子附近再找个空格子, 把关键字为x2的元素放进去。记下此时关键字为x2的元素位于m号格子上。万一接下来又凑巧有一个关键字为x3的元素, 使得m=h2=f(x3)又该怎么办?那就在m号格子附近再找一个空格子……以此类推,每次要是发现算出的哈希值对应的格子已经被占了, 那就在附近再找一个空格子,这种解决冲突的办法统称开放地址法。
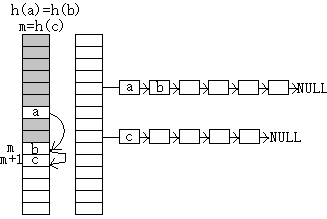
开放地址法和链表法
另一种解决方法是,以这些哈希表中的格子为起点建立链表,曰链地址法,或者放弃链式而采用顺序存储,这就是公共溢出区法。 要是有想象力的话,你甚至可以想出把输出的哈希值作为输入再来一次哈希,曰再哈希法。总之,要么另外开辟空间放发生冲突的元素,要么重新采用一套规则放它们。
注意,哈希存储时用的哈希函数最好不要采用密码学中的摘要函数, 因为那样的话,哈希函数计算过程太复杂,确定存储位置时消耗算力太大,费电费时间。
在发生冲突的地方附近再找一个空格子,具体怎么找呢?开放地址法也分很多种类。我们设初始哈希值h
有一次的方法就有二次的方法:向右1格,向左1格,向右4格,再向左4格,向右9格,再向左9格…… 每回发生冲突,依次取自然数列的值平方一下,先向右再向左。 2 相应地{dk}={1,-1,4,-4,9,-9……}。和线性探测相比,二次探测向外扩展的速度快,能很快找到一个远处的空格子,在哈希表整体上比较满的时候好用。
还有一种近乎变态的做法是直接让d变作随机数,要是再冲突了就再随机,直到以空格子为止。当然,出于简化,一般可用伪随机数。
辛酸网 ©版权所有