数学和计算机科学板块_辛酸网
数据结构与算法12
BY TSherry
现在将图的两种遍历。DFS是深度优先搜索,即一条道走到黑,步步深入,层层回溯的遍历。 BFS是广度优先搜索,是层层环绕,步步剪枝的搜索。无论是哪种遍历都要从某一个结点开始的,你可以从放在结点的数组中0还元素直接开始。 我们取一个结点作为起点,进行DFS的过程是:
准备工作:对所有结点都设立一个是否已经访问过的标志visited,初值0
执行DFS遍历函数如下:
对于起点,如果visited标志为0,则:
对其自身进行一般性的访问操作,例如显示data在屏幕上等
其自身的visited标志设为1表示已经访问过了
根据其所关联的边,遍历每一个与之邻接的结点,找到一个visited标志为0的,执行
以这个结点为起点,递归地执行DFS遍历函数
如果在找完了,没找到visited标志为0的邻接结点,退出当前函数,回溯
对最开始的起点干完了DFS遍历函数,其联通的这部分就搜索完了。
DFS无疑是递归算法的一种,从一个结点开始,对该自身先进行访问操作,打下标记宣布其已被访问过。 接着在其邻接的结点中挑一个未被访问过的递归进行上述处理,找不到的话就回溯。
在解决一些复杂的问题时, 问题状态可能会构成复杂的图,用DFS求解时最先访问的结点最晚回溯,因此程序需要一个栈保存过去干过的事情。 相反地,BFS则是用队列记录过去干过的事情。BFS是广度优先搜索,核心逻辑是:从一个起点开始,在对其进行访问操作后, 遍历其邻接的所有结点,如果没访问过就分别进行BFS遍历处理。指定一个最开始的起点后,看其过程:
准备工作:对所有结点都设立一个是否已经访问过的标志visited,初值0
对起点进行一般性的访问操作,例如显示data在屏幕上等
其自身的visited标志设为1表示已经访问过了
对起点执行BFS遍历函数如下: 遍历其所有的邻接的结点,先后进行:
如果visited标志为1,说明已经访问过了,跳过
如果visited标志为0,说明还没访问过,访问,入队
对队列里的每一个结点进行,执行BFS遍历函数
邻接的结点遍历完了,就退出函数,回溯
对最开始的起点干完了BFS遍历函数,其联通的这部分就搜索完了。
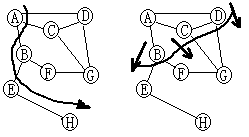
上例子:
|
左为DFS,从A开始过程如下:
| 访问序列:ABEHFGCD |
|
右边的BFS例子过程如下:
| 访问序列:ABCDEFHG |
有向图中的搜索,肯定是要沿着边的方向的,请注意。
对于带权联通图,有这样一棵树:包含图中全部结点,其边上权重之和最小,这件事最小生成树。 最小生成树的获取有普利姆算法和克鲁斯卡尔算法两种,都属于避圈法————导出过程中避免成圈。 生成树都是一步一步逐渐建立起来的。
普利姆算法需要先指定一个结点作为起点,从这个起点开始构造树。起点可以选择任意一个。 该算法的内容是:每次都要将生成树已有部分视作一个小的整体,从图中其余部分里找一些这样的边: ①这条边和这个整体中的一个结点关联,也和一个尚未在该整体中的结点关联;②和整体中其它的边不能成环。 在找到若干条符合这些条件的边后,从中挑选权值最小的那条及其关联的尚未在整体中的结点,加入到这个整体。 就这样,生成树包含的结点越来越多,直至占据图中所有结点。下面这个就是百度百科中的一个例子。
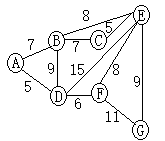
不妨从A开始。算法过程如下:
BD与A相连,最短边AD为5,边AD及结点D入树
AB,BD,DE,DF相连,最短边DF为6,边DF及结点F入树
AB,BD,DE,EF,FG相连,最短边AB为7,边AB及结点B入树
BC,BE,DE,EF,FG相连,最短边BC为7,边BC及结点C入树
BE,CE,DE,EF相连,最短边CE为5,边CE及结点E入树
EG,FG相连,最短边EG为8,整体成环,废
选取EG,边EG及结点G入树
至此,树中边有AB,BC,CE,AD,DF,EG
普利姆算法是一种生长式算法,而克鲁斯卡尔算法是一种汇聚式算法。
克鲁斯卡尔算法的内容也很简单:每次都是在生成树的已有部分之外, 从整个图的所有边里挑一个权值最小的,并且要求避免和生成树内已有的边构成圈,直到所有结点都形成一个连通图为止。
克鲁斯卡尔算法中过程的每一步,都是将生成树的已有部分视为一个个碎片, 在确保不成环的条件下用权值最小的外来的边将碎片一个个连起来,直到所有碎片被连上去为止。同样是上面的例子,过程如下:
首先,整体上最短边AD为5,形成碎片AD
发现余下最短边CE为5,形成碎片CE
发现余下最短边DF为6,碎片AD扩展为ADF
发现最短边AB与BC为7,乱选一个BC,碎片CE扩展为BCE
发现最短边AB为7,相连形成碎片ECBADF
发现余下最短边EF为8,ECBADFE成环,废
取次短者EG,大号碎片扩展为生成树
本轮获取最小生成树同上
辛酸网 ©版权所有