数学和计算机科学板块_辛酸网
数据结构与算法23
BY TSherry
对单纯的BFS有很多改造,其中最基本的就是分支限界与剪枝。在解决一个复杂的问题时,答案的状态空间很多时候会以树状的方式存在。 我们知道,BFS需要一个队列,先扩展出的子结点会先被单独处理,扩展出这个子结点的子结点以后再退出而不回溯。不过这也涉及到一个问题——很多时候我们要找的不仅仅是可行解还得是最优解。 但是那些结点下面的子树更可能出现最优解呢?如果某些结点下面更可能出现最优解,我们是不是应该先从这里找答案以节省时间呢?假使有一种办法,能够让我们推测出最优解出现在不同子树中的概率,我们完全可以先在概率最大的那个里面寻找。
为此,我们可以建立一个评估函数对队列中的每一个结点进行评估,最容易出现最优解的子树,其根节点就是队列中的某一个结点。 我们先从这个结点开始,将其子结点扩展到队列里,然后如法炮制。于是,这个队列就不再是经典意义上的队列了,因为入队出队并非按照时间顺序,每次加入新结点时会通过评价函数重新排序,出队时只会把具有最值的结点排除。 由此,被评估函数在入队时重新排序、出队时最值者最先的一维数据结构,叫做优先队列。
例如在0-1背包问题中,n个东西都有放和不放的两种可能,总体上就是2n种情况。 自根节点宣布启动求解过程开始,第1个东西放不放,第2个放不放……这就构成了二叉树。我们可以用BFS遍历这棵树。但为了节省时间,每次下决定前要考虑先对剩下的哪件物品进行决策。 这个意思是:我们判定一个物品放不放之前,要先搞清楚对哪个物品思考这个问题。只要挑得好,问“放不放”的问题次数少,搜索时涉及的树的深度也小。
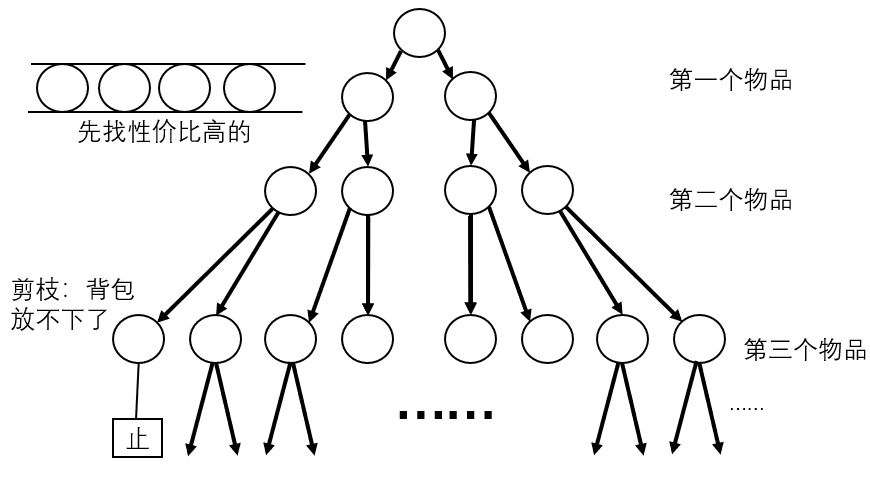
至于评估函数,我们可以取已经结点中选取的所有物品总价格与占用总体积之比,取最低的那个就行了。至于这个评估函数准不准确,肯定不准确。 (准确的话谁搜索啊,直接贪心上呀!)话说也有一种可能是,后面的东西放不放还没去想,前面的东西已经把背包占满了,这时就不应该继续往下扩展子结点了。因为背包放不下,如果此时溢出了空间,则该结点必定无效,其下没有可行解,更谈不上最优解。 若是刚好放满,也许这个刚好就是最优解,那就记下来和后面的方案作比较。直到最后,我们会发现背包放得下之前提下,使得总价格最大的放东西方案的。
说到更加一般的问题上,一旦状态空间的结点中,我们发现有一些结点及其子树不存在最优解甚至没有可行解,那我们也没必要在那里继续往下搜索了。于是,状态空间的树会有一部分被删除,相应的结点不会继续扩展,这就是剪枝。对一个结点进行处理时,我们还可以对其子树中的解的优度进行预测。 正常情况下你确实猜不准下面的解有多优,但也许你能精准猜测它们的下界或是上界。那样的话,要是你发现子树里最优的解都不如当前已经发现的最优的解要好,那就用不着继续往下搜了。反之,你发觉这里面最烂的解都比当下最优的解要好,那就果断过去!这就是分支限界。
对于树如此,很多时候更一般的图也是类似的道理。不过在图中的遍历,你需要事先检测一下当下这个结点是不是已经被访问过了,如果没有再看要不要扩展其子结点。 在状态空间树中,一个叶结点往往意味着问题的一个完整的解。
上述内容表明了BFS比DFS更加常用的原因,即改造后的BFS能灵活地减小时间开销,但这并不意味着DFS不可改造,恰恰相反,DFS同样能够使用这些手段来优化,只不过被评估函数优化后的栈已经不再是经典意义上的栈,而是对应于优先队列的优先栈,虽然二者实质上没什么差别。
贪心算法在很多时候是不行的,但在动态规划以及分支限界、启发式搜索等复杂搜索算法里,可以作为辅助函数以加速求解,比如估价、限界等。
启发式搜索是指利用问题中的启发信息来指导图论搜索工作,它既有基于BFS的也有基于DFS的,但前者居多。启发信息的指导工作包括:搜索方向的优先、分支限界和剪枝。 但采用搜索方向的优先、分支限界和剪枝的图论搜索不一定是启发式搜索,核心判断逻辑在于这些指导工作是否使用的了问题中的启发信息。可话说回来,一个图论搜索是不是启发式搜索的区分界限并不是绝对的。 此外我们还需意识到另一点——并非所有的图论搜索都要求找到最优解,有些时候只要是个比较优的解就行了,甚至是个可行解就够了。这时搜索算法当然不需要也几乎不可能遍历所有的完整的解, 在状态空间内,往往是在多个目标结点中,碰到一个可行的目标结点就停了(树中多为叶结点)。至于这个目标结点对应的解好不好,大概率不是全局最优解,但也是不劣的解。
A算法是典型的启发式搜索算法,用于解决最短路径问题。它的核心思想是建立一个估价函数f(n)=g(n)+h(n),其中g(n)表示从起始结点到此处的代价,h(n)表示从此处到目标结点的代价。二者加起来就是:按照当前的选择所预测的,从起始结点到目标结点的总代价。 我们要求让这个代价尽可能小,于是在广义的BFS之优先队列中,挑选f函数值最小的那个先对其子结点进行扩展。当然,这里所说的总代价通常是预估而非准确的。只不过g(n)的值确实可以精准算出来, 因为这个对应于已经作出的选择,已经走过的路有多长,在走路过程中还是可以测量出来的。当h(n)=0恒成立时,如果我们要遍历全部的目标结点而非只是一个,那么它就退化为迪杰斯特拉算法;若h(n)=0且边上的权重都为1,则退化为一般BFS。
我们设h*(n)为从此处到目标结点的实际代价。因为h(n)只是预估的从此处到目标结点的代价,和实际值相比可能大也可能小。 所以当h(n)和h*(n)相比偏大时,也许真正的最优解就在那里,但h(n)的偏大造成f(n)偏大,使得优先队列反而将其放在后面,甚至可能将其剪枝。所以,h(n)和h*(n)的差值是衡量A算法实现得好不好的重要指标。 而在具体问题中,倘若你能找到一种预估方法,使得预估出来的h(n)≤h*(n)恒成立,那么带有最优解的子树或是图的片段就不会被剪枝,甚至被优先队列放在靠前的位置,那样的话就能保证找到最优解了,而且还快些。 如上述者,被评估策略改造过使得h(n)≤h*(n)恒成立的启发式BFS搜索,叫做A*算法。和A算法相比而言,A*算法效率高,且能保证得到全局最优解。
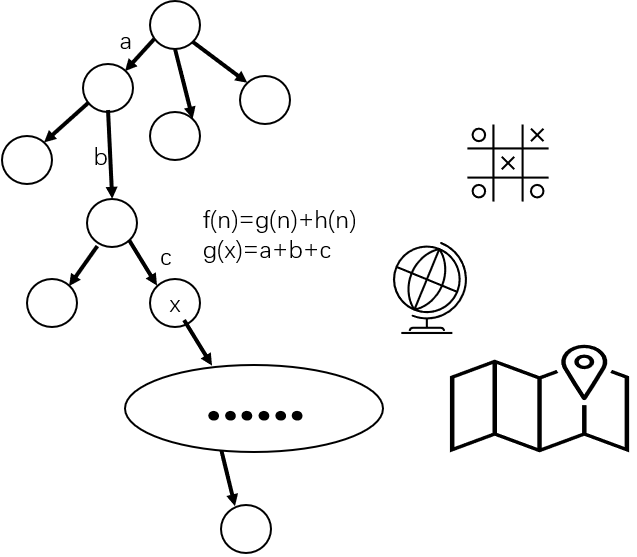
启发式搜索的应用包括但不限于:游戏角色的自动寻路、外卖员的配送路径规划、日常出行的地图导航、机器学习、自然语言处理等,在人工智能中应用广泛。
启发式搜索的概念后来被进一步泛化为启发式算法,即使用了启发信息的算法。遗传算法、蚁群算法、量子退火算法等模拟算法都以此为基础发展而来。
P问题是指能在多项式时间内解决的问题,如果不行,那就叫NP问题。是否所有的NP问题是或者说都能转化为一个P问题?不知道。这是一个21世纪的世界难题。
目前学术界多数认为二者不等同,但是为什么呢?不知道。
完结撒花✿✿ヽ(°▽°)ノ✿
辛酸网 ©版权所有